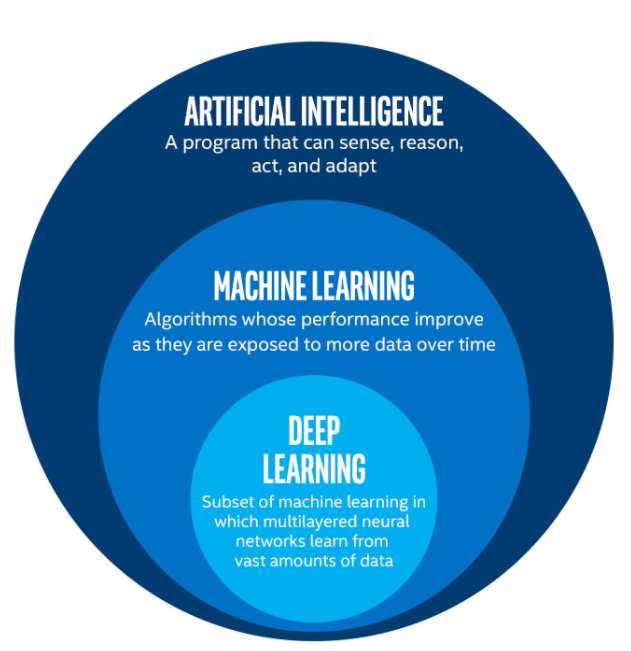
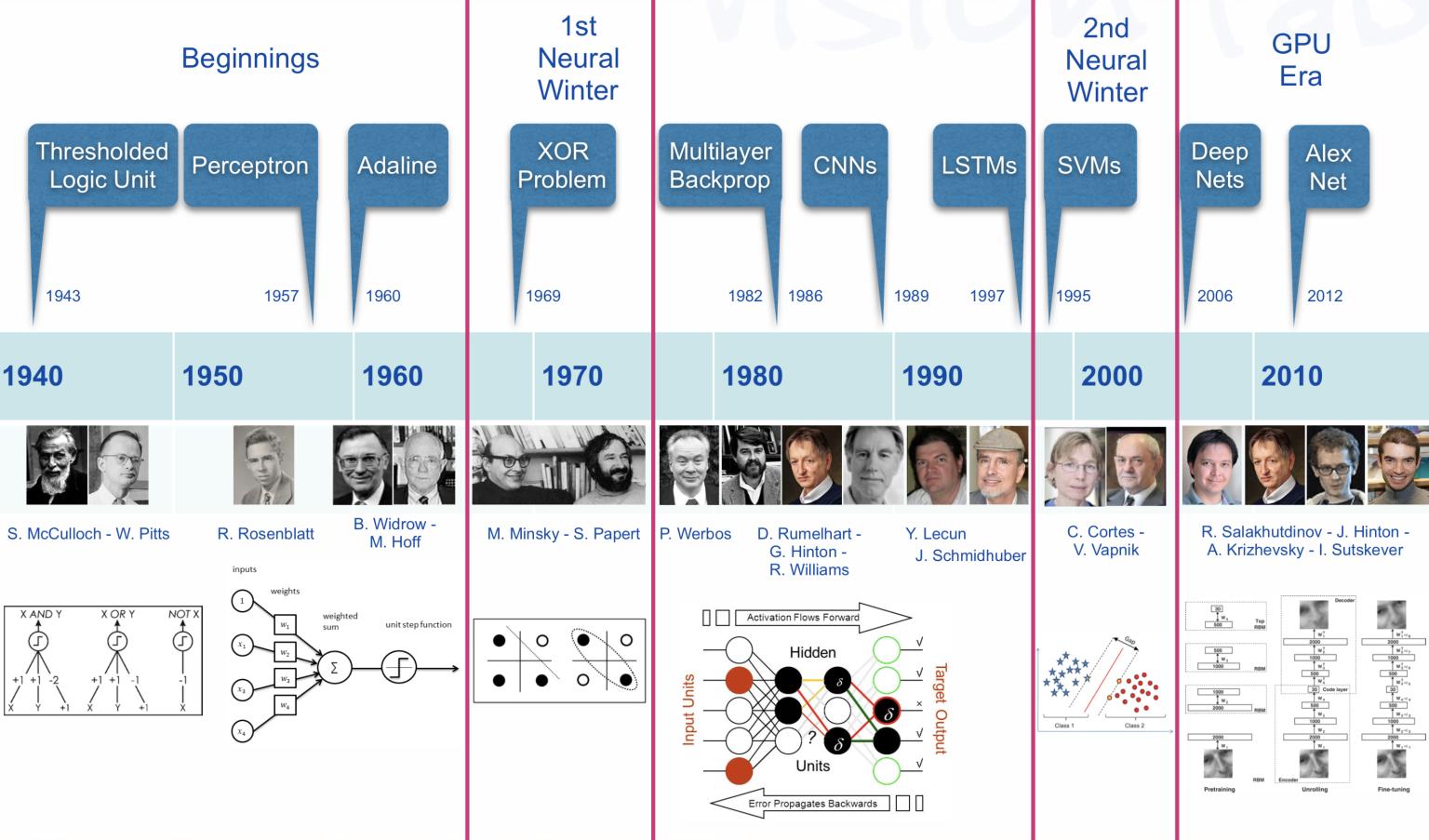
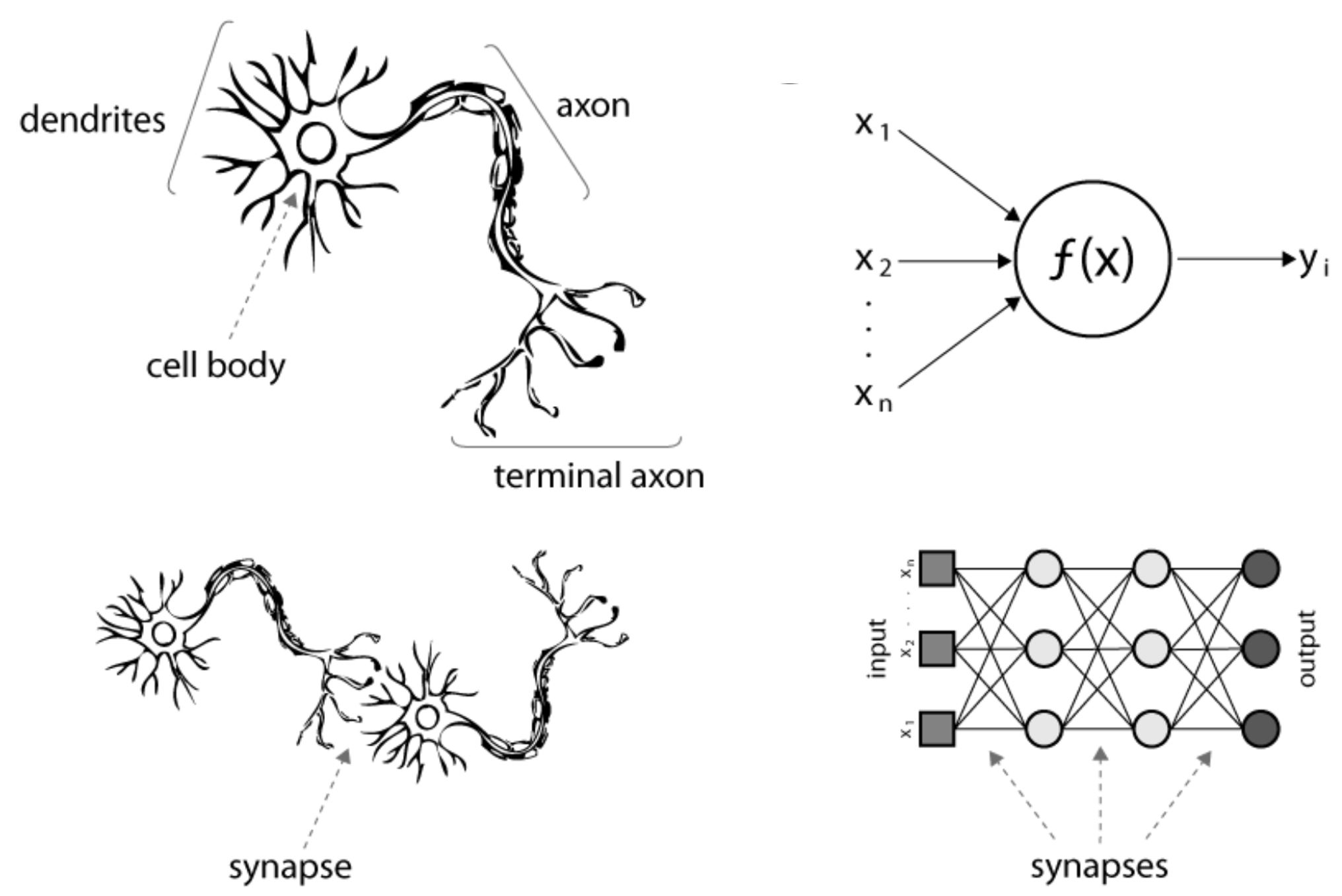
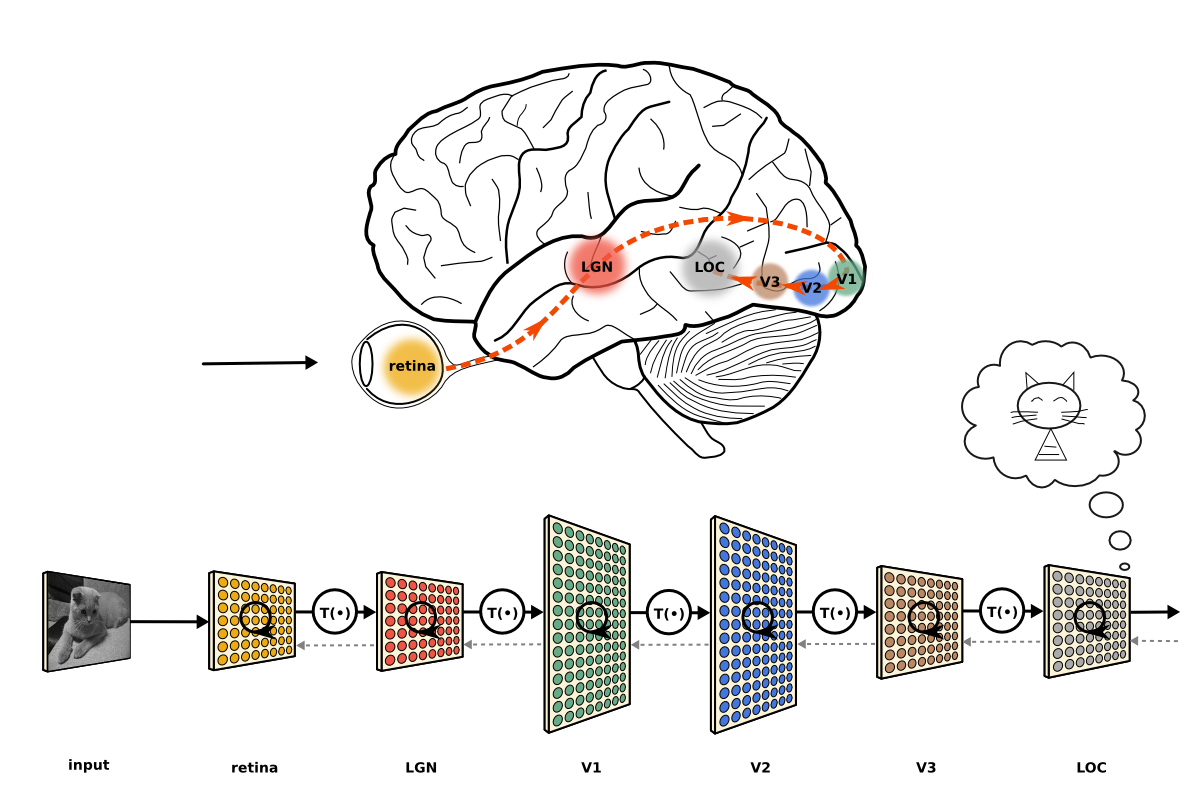
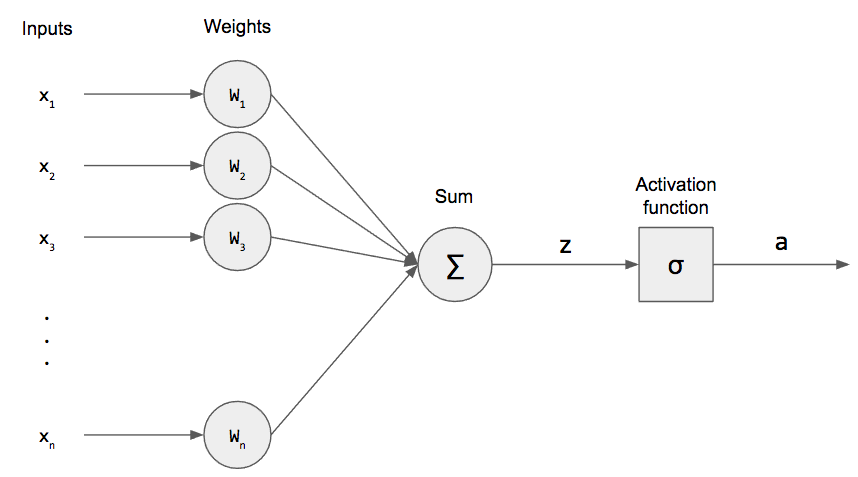
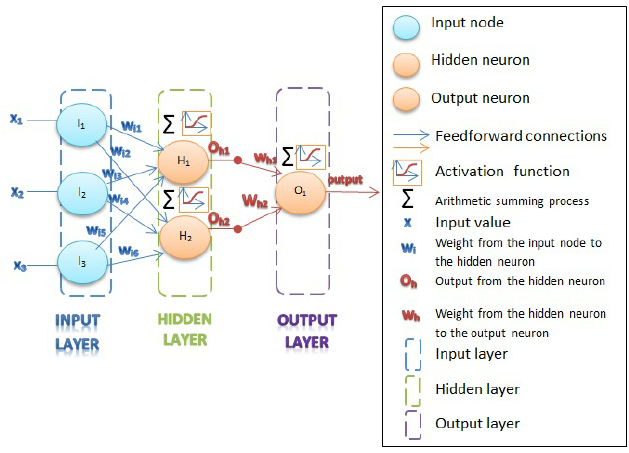
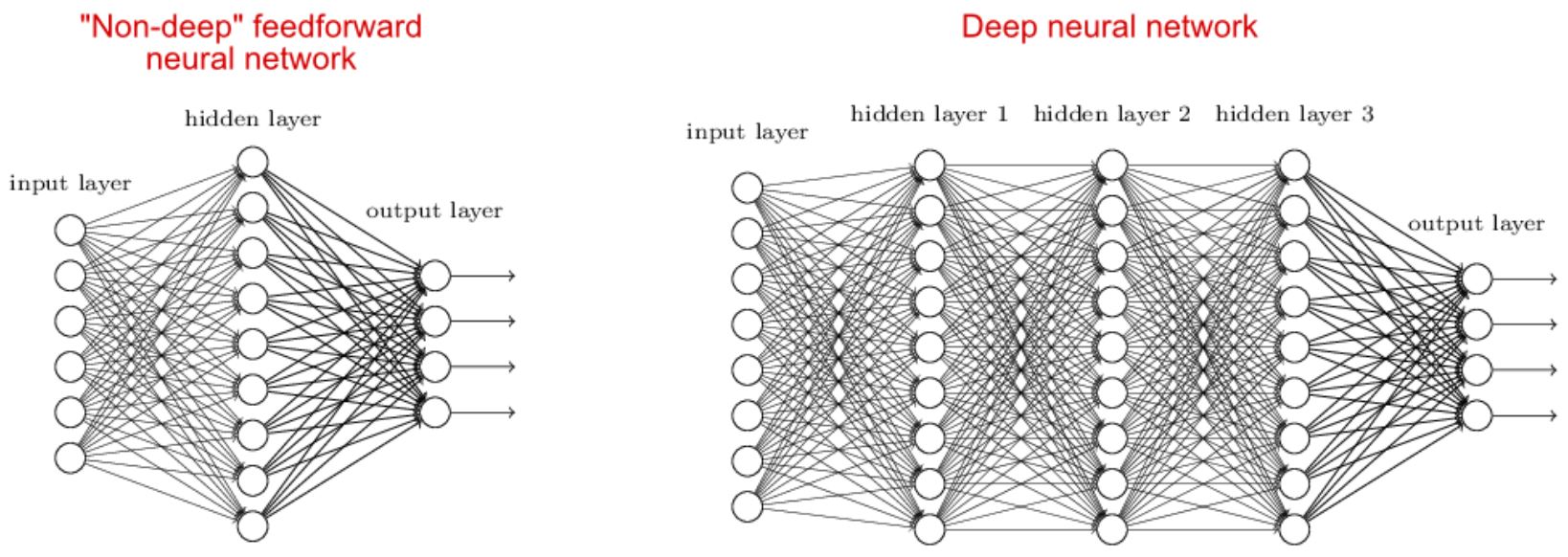
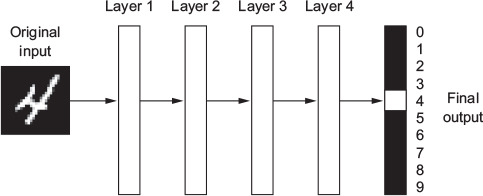
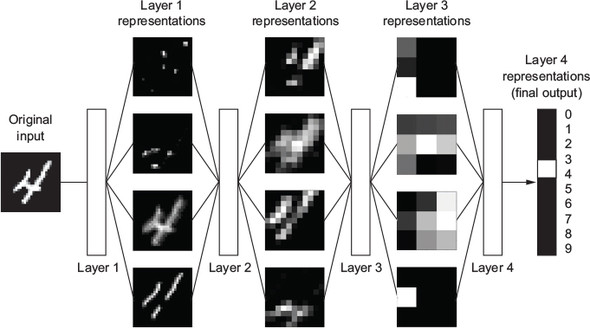
Let us consider three functions \(f^{(1)}\), \(f^{(2)}\), and \(f^{(3)}\) connected in a chain, to form \(f(x) = f^{(3)}(f^{(2)}(f^{(1)}(x)))\)
\(f^{(1)}\) is called first layer (or input layer), \(f^{(2)}\) second layer (or first hidden layer), and so on… the overall length of the chain gives the depth of the model
The final layer of the network is called the output layer \(f^*(x)\)
During neural network training, we drive \(f(x)\) to match \(f^*(x)\)
Because the training data does not show the desired output for each of the intermediate layers, these layers are called hidden layers
The dimensionality of the hidden layers determines the width of the network
Deep NNs overcome an obvious defect of linear models, that is their limited capacity to linear functions approximation; NN understand complex interactions between input variables.