Intro to GPT Models
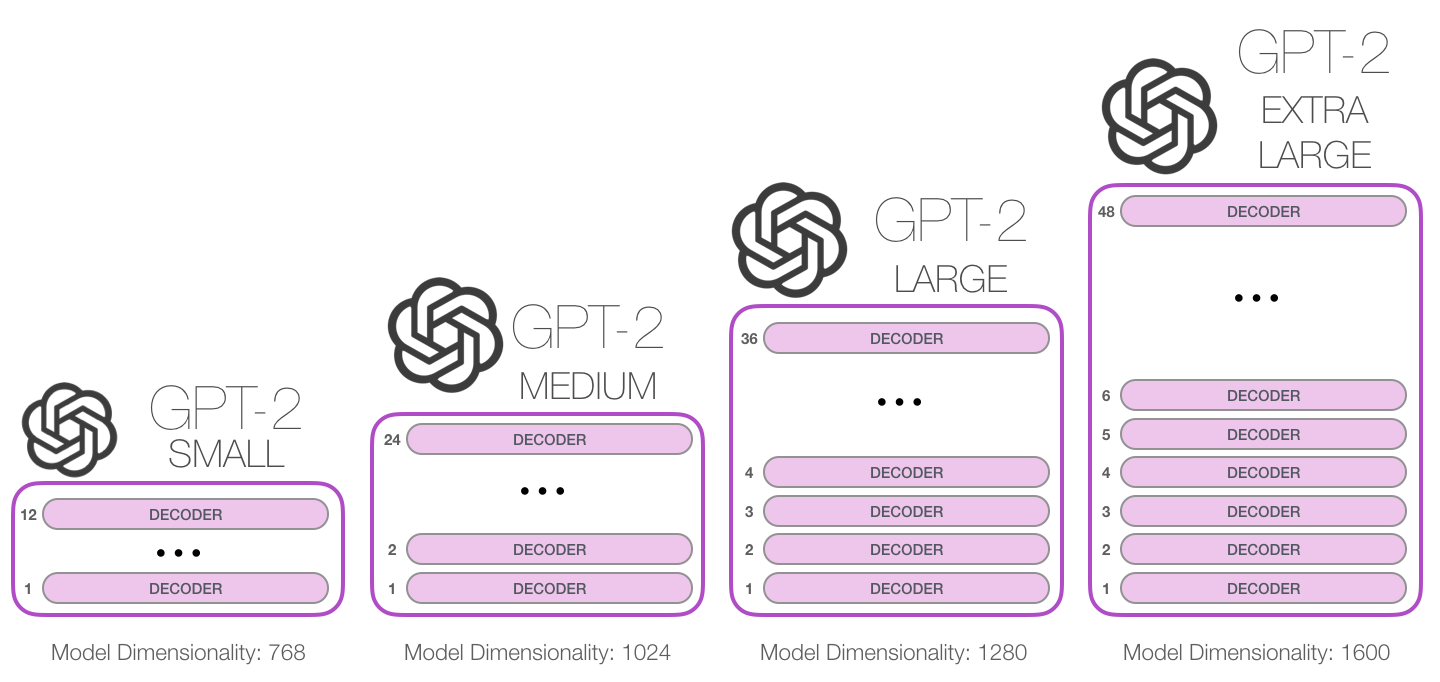
GPT models (Decoders) play a crucial role in generating subsequent words in tasks like text translation or story generation, providing outputs along with their probabilities. They utilize attention mechanisms twice during training: initially, Masked Multi-Head Attention, where only the beginning of a target sentence is revealed, and later, Multi-Head Attention, similar to encoders. In traditional transformer models, decoders interact with encoders by using the encoder’s outputs to assist in tasks like sentence translation. However, GPT models adopt a unique approach by relying solely on a decoder, compensating for the absence of an encoder through extensive training on large datasets. This allows for embedding a vast amount of knowledge within the decoder. ChatGPT further advances these techniques by integrating human-labeled data to address issues such as hate speech and employing Reinforcement Learning for enhanced model quality.
Notebooks - Basics
Notebooks - Applications
- TM Applications - LangChain
- TM Applications - LanceDB
- TM Applications - LanceDB - Solutions
- TM Applications - RAG