Basics of NLP
NOTEBOOKS:
============================================
How ‘computer’ understands text?
============================================
Imagine someone who cannot hear and uses sign language to communicate. To understand them, you need to learn the specific signs they use to express words and ideas.
The signs represent the meaning of words, but they aren’t the words themselves—just symbols that convey the message.
Similarly, computers don’t understand human language directly. Instead, we translate text into a format they understand—like sign language for machines. This ‘machine sign language’ is a numerical representation of text, called ‘vectors’ or ’embeddings.’
Each word, phrase, or sentence is converted into a series of numbers that capture its meaning.

============================================
Problems? Language is weird! [1]
============================================
Something that is easily understood by humans is not always easily understood by computers—and vice versa! Placing additional word in to sentences can change the main message, but it doesn’ always convey the same message when converted into a numerical representation of text—and vice versa!

Languages are full of synonims and words that have several meanings. Humans understand the correct meaning by knowing the context.

Punctuation marks can change the meaning of the sentence.

============================================
Level of analysis - One Big Text (Corpus) vs Many Short Texts
============================================
The difference between analyzing a large corpus vs. multiple short texts
One Big Text or Corpus of Texts:
- Focuses on extracting meaning, patterns, or structure from a long or cohesive text.
- Examples: Books, academic articles, or a collection of documents.
- Example: Analyzing academic article abstracts for topic modeling or sentiment analysis.
Many Short Texts:
- Involves processing multiple, often disconnected, texts that are short and concise.
- Examples: Social media posts, product reviews, or comments.
- Example: Processing Amazon reviews to determine customer sentiment or product popularity.
What Are We Analyzing in NLP?
============================================
1. Text as such
- Analyzing broad characteristics of the entire text or corpus.
- Examples:
- Topics: Identifying themes or subjects within the text (e.g., topic modeling).
- Sentiment: Understanding the emotional tone (e.g., positive, negative, neutral).
- Language Modeling: Predicting the likelihood of text sequences.
- Similarity: Measuring how similar two texts or documents are (e.g., document similarity, semantic similarity).
2. Elements Within Text
- Analyzing smaller components or structures in the text.
- Examples:
- Entities: Identifying named entities (e.g., people, organizations, locations) within the text.
- Relations: Understanding relationships between entities (e.g., person works at a company).
- N-grams: Extracting consecutive word sequences (e.g., bigrams, trigrams) to analyze co-occurrences or phrase structures.
==========================================
From simple towards more complicated methods
==========================================
In the next few slides, we will look at different methods used in NLP:
1. Bag of Words (BoW)
2. TF-IDF
3. Word2Vec
Bag of Words (BoW)
============================================
What is it?
- It is very simple and easy to use.
- It uses the numerical representation of text that can be easily understood by machines.
- It has a wide range of applications in many different fields like Natural Language Processing, Machine Learning etc.
- It provides an efficient way for computers to understand human language.
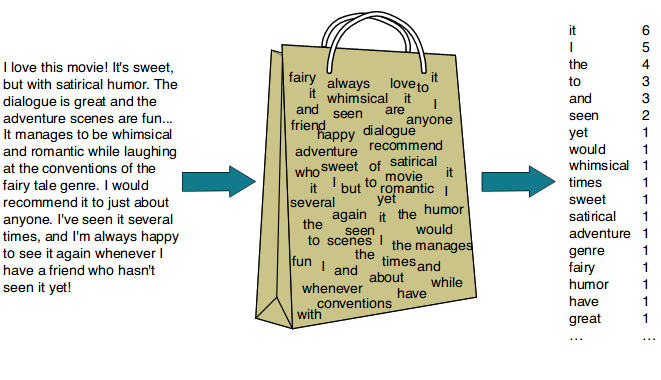
| Steps: 1. Tokenize the input sentence into individual tokens (words). 2. Remove stop words from the tokenized list if required. 3. Create a dictionary of each unique word. 4. Represent each text as a vector of word counts or frequencies. | 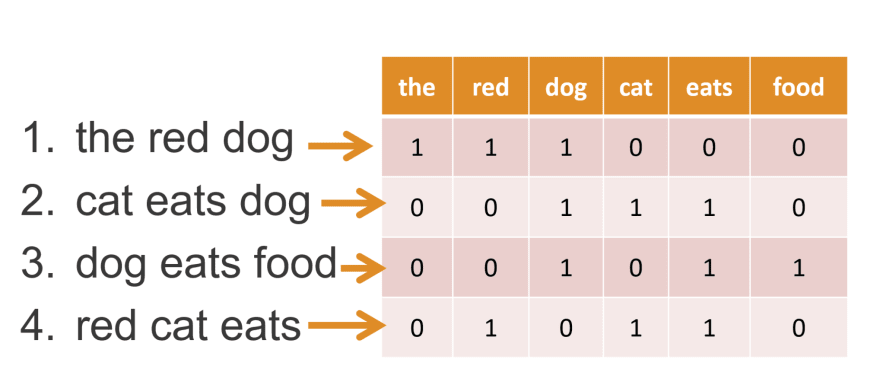 |
TF-IDF (Term Frequency - Inverse Document Frequency)
============================================
A statistical measure used to evaluate how important a word is to a document within a corpus.

Term Frequency (TF): Measures how often a word appears in a document.
Inverse Document Frequency (IDF): Measures how common or rare a word is across all documents.
Advantages:
- Highlights important words specific to a document while down-weighting frequent terms
- More informative than BoW for distinguishing relevant terms in large corpora.
| Example BoW: A word like "the" might be very frequent, but it's not important. TF-IDF: Words like "science" or "research" in an article about technology would get a higher score because they are less frequent in general but more important for the specific document. |  |
Word2Vec
============================================
A deep learning-based model that transforms words into continuous, dense vectors (embeddings) that capture semantic meaning.
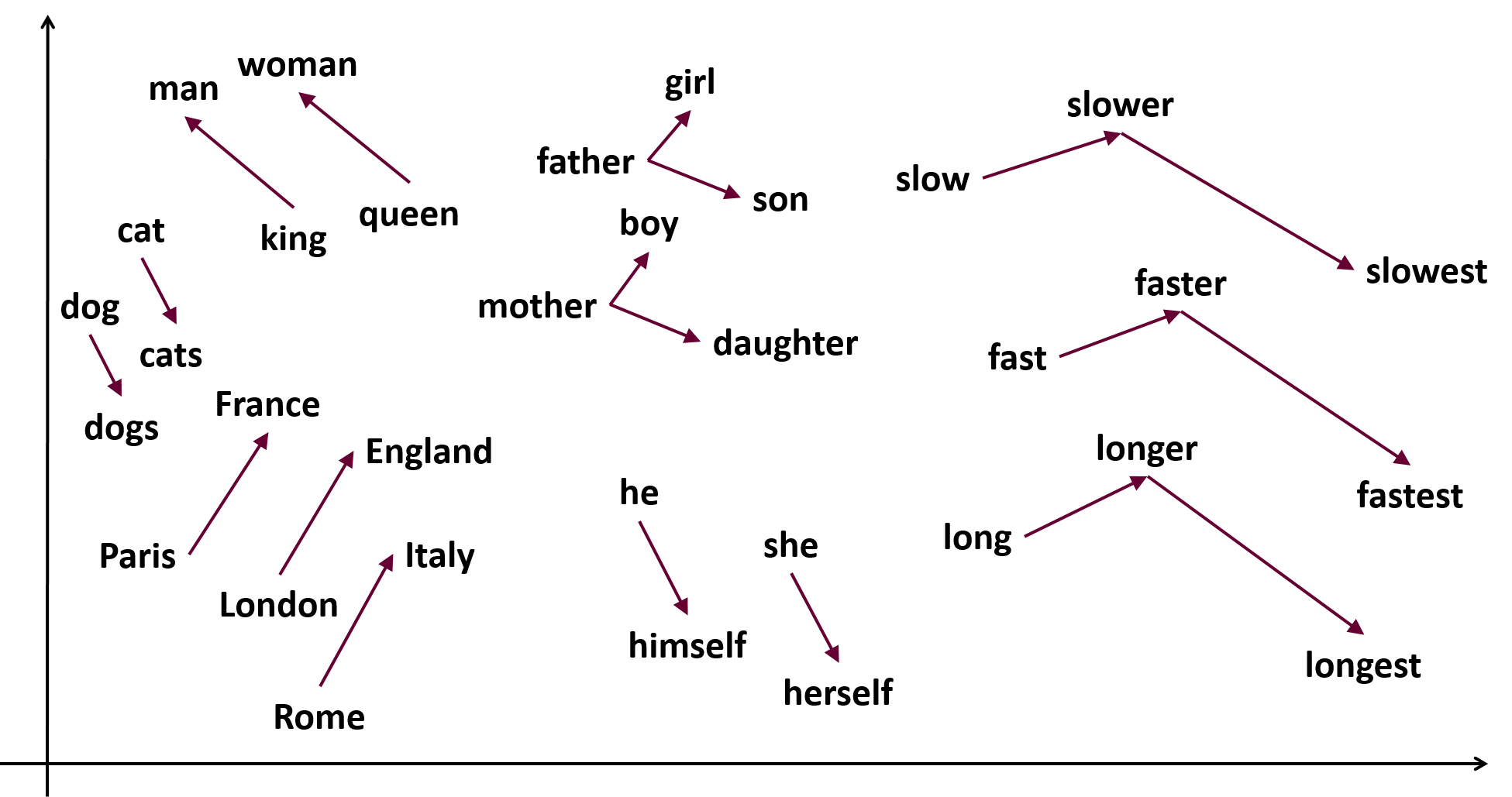
Advantages:
- Captures word meaning and context.
- Efficient for representing large vocabularies in a low-dimensional space.
- Can perform word arithmetic (e.g., “king” - “man” + “woman” ≈ “queen”).
Limitations:
- Requires large corpora for good performance.
- Doesn’t directly handle out-of-vocabulary words.
- Context is limited to a fixed window size.
Comparison: Word2Vec vs. TF-IDF vs. BoW
============================================
| Feature | Word2Vec | TF-IDF | BoW |
|---|---|---|---|
| Representation | Dense vector embeddings | Weighted word frequencies | Word counts |
| Context Awareness | Yes, considers surrounding words | No, treats words independently | No, treats words independently |
| Semantic Meaning | Captures semantic relationships | No, only counts importance based on corpus | No, only counts word frequencies |
| Dimensionality | Low (dense vectors) | High (sparse matrix) | High (sparse matrix) |
| Common Use Cases | Similarity, analogy, NLP tasks | Text classification, relevance scoring | Text classification, simple tasks |