Seq2Seq & Transformers
NOTEBOOKS:
Seq2Seq: The Next Step in NLP After Word2Vec
==================================
Word2Vec was great at learning word representations, but it lacked the ability to process or generate sequences (e.g., sentences).
What Seq2Seq Introduced:
- Seq2Seq models are designed for tasks where both input and output are sequences, such as:
- Machine translation (English to French)
- Text summarization
- Chatbot responses
How Seq2Seq Works:
==================================
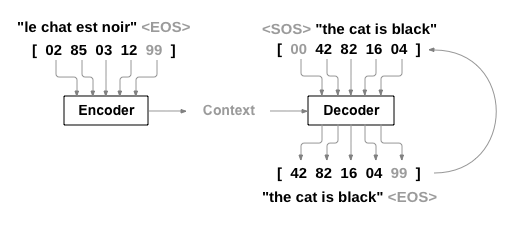
- Encoder-Decoder Architecture:
Encoder: Processes the input sequence (e.g., a sentence) and converts it into a fixed-size vector (context vector).
Decoder: Takes the context vector and generates the output sequence (e.g., the translated sentence).
==================================
From RNN to LSTM to Transformers (seq2seq)
==================================
1. RNN (Recurrent Neural Networks)
Introduced: 1980s
Strength: First model to handle sequences by using a “hidden state” to retain information.
Limitation:
- Vanishing Gradient Problem: Struggles to retain information over long sequences.
- Difficult to process long sentences or paragraphs.
- Sequential processing makes them slow to train.
2. LSTM (Long Short-Term Memory)
Introduced: Paper published 1997
Strength: Improved version of RNN designed to solve the vanishing gradient problem.
Key Feature:
- Gating Mechanism (input, forget, output gates) allows selective retention of information.
- Better at handling long-term dependencies.
Limitation:
- Still processes words sequentially, limiting training speed and efficiency.
3. Transformers
Introduced: 2017 (by Google researchers)
Strength: Revolutionized sequence processing with self-attention and parallelization.
Key Features:
- Self-Attention: Enables the model to focus on all parts of the input sequence at once, handling long-range dependencies effectively.
- Parallel Processing: Unlike RNNs/LSTMs, Transformers process all words simultaneously, making them much faster to train.
Results: Can handle massive datasets and generate state-of-the-art results in translation, summarization, and text generation (e.g., GPT-3, BERT).
Why Transformers Are Important
==================================

Transformers overcame these challenges:
- Highly parallelizable, allowing efficient training on large datasets.
- Scales well with data—models like GPT-3 were trained on 45 terabytes of text!
Key elements of Transformers [1]
==================================
Positional Encodings:
- Instead of sequential processing like RNNs, Transformers use positional encodings to capture the order of words.
- Words are tagged with a position number (e.g., 1, 2, 3), and the model learns how to interpret the order during training.
Example: ‘hot dog’ together have differnt meaning as ‘dog that is hot’
Attention Mechanism:
Attention allows the model to focus on specific parts of the input sentence when making predictions
It works like a heatmap for how much focus the model gives to certain words.
- Self-Attention:
- An extension of attention where the model looks at the whole input sequence to understand the meaning of a word in context.
Example:
The animal didn’t cross the street because it was too tired.
The animal didn’t cross the street because it was too wide.
Self-attention allows the model to recognize that “it” refers to “the animal” or “the street”!
Transfer Learning: Fine-tuning Pre-trained Models
==================================
Transfer learning is a crucial technique in NLP, especially with the advent of large pre-trained models like BERT (Bidirectional Encoder Representations from Transformers), GPT, and others. These models are trained on massive datasets and can be fine-tuned on specific tasks such as binary classification (e.g., classifying reviews as positive or negative) by leveraging their learned knowledge.
How Transfer Learning Works:
Pre-training:
- A large model like BERT is first trained on a massive corpus of text to learn general language patterns.
- The model learns rich representations of language, such as grammar, semantics, and context.
Fine-tuning:
- After pre-training, the model is fine-tuned on your specific dataset (e.g., sentiment analysis or classification tasks).
- During this phase, the model adjusts its weights based on the specific examples in your dataset to learn the target task.
Example: Binary Classification with BERT
- Dataset Preparation: Prepare a dataset with two classes (e.g., positive and negative reviews).
- Model Setup: Use a pre-trained BERT model from libraries like HuggingFace’s Transformers.
- Fine-tuning: Train the BERT model on your dataset, adjusting the final layer for a binary classification task.
- Evaluation: After fine-tuning, evaluate the model on unseen test data to check performance.
Advantages of Transfer Learning:
- Faster Training: Pre-trained models already know a lot about language, so they require less data and time to train on specific tasks.
- Better Accuracy: Transfer learning often leads to improved performance, especially when data is scarce.